non-scalable VS scalable spinlock

自旋锁是一种会让尝试获取它的线程陷入循环 (“自旋”)并不断检查锁是否可用的锁 1。
和mutex 不同,mutex 可以睡眠,将cpu让渡给其他的程序,而自旋锁则是占据着cpu资源忙 等。忙等最主要的优点是,避免了调度所带来的上下文开销, 可以提升等锁进程获得锁的延 迟。另外,如果加锁的临界区很小,自旋锁忙等所带来的开销,可能会小于上下文切换的开 销,自旋锁的收益就会非常大。所以,自旋锁适用于临界区小的场景。
overflow
本文主要是来讲述, spinlock 的可伸缩性(scalable). 可扩展性是指系统处理不断增长的 工作量的能力。软件系统的可扩展性定义之一是,可以通过向系统添加资源来实现 2. 而对于spinlock而言, 如何增加其工作量呢? 增加并行调用spinlock的cpu数量
在介绍之前我们先思考下,自旋锁和 “smp”, “up” 关系3。首先按照自旋锁的 逻辑,自旋锁的临界区是不能睡眠的,这个动作非常危险,容易造成死锁。所以 UP下(单 CPU) 自旋锁是没有意义的。
所以自旋锁是服务于smp的。而随着cpu的发展,cpu的核心越来越多, 并行调用spinlock的 数量也大大增加。而传统的spinlock则在 smp 场景中体现出了 non-scalable。
接下来的章节,我们首先介绍一些硬件背景,包括
- cache snoop method
- cost of cache coherence
而之后,便介绍因cache coherence 给spinlock带来的性能影响。最后,展示下scalable spinlock 带来的性能提升。
文本主要参考老黄和狗哥的文章4,5 以及
Non-scalable locks are dangerous论文6.
cache coherence
关于cache coherence 很值得单独写一篇文章去总结( TODO ). 这里我们简单看下
snoop-based coherencenon-scalable 问题。以及其改进版本directory-based coherence给spinlock 所带来的non-scalable问题。本节内容(包括大量的图片) 均参考
CMU 15-418/618 lecture7, 8
为了降低cpu访问内存的延迟, 在cpu 和 内存之间加了一层cache。但是在smp架构下,每个 cpu都有自己的cache,所以相当于main memory 所存储的数据在各个cpu上都有了副本。 这回带来一致性问题。而cpu硬件实现了一套无需软件参与的缓存一致性协议,用来维护各 个 cpu cache之间以及和主存之间的一致性。
在早期的实现中,cpu数量不多。cache一致性使用snoop-based的方式,该方式的特点是 广播,而随着cpu数量越来越多,尤其是NUMA架构的兴起,广播的代价越来越大, snoop-based方式则变得non-scalable. 于是大佬们搞出了非广播的点对点的 directory-based coherence一致性协议。
snoop based
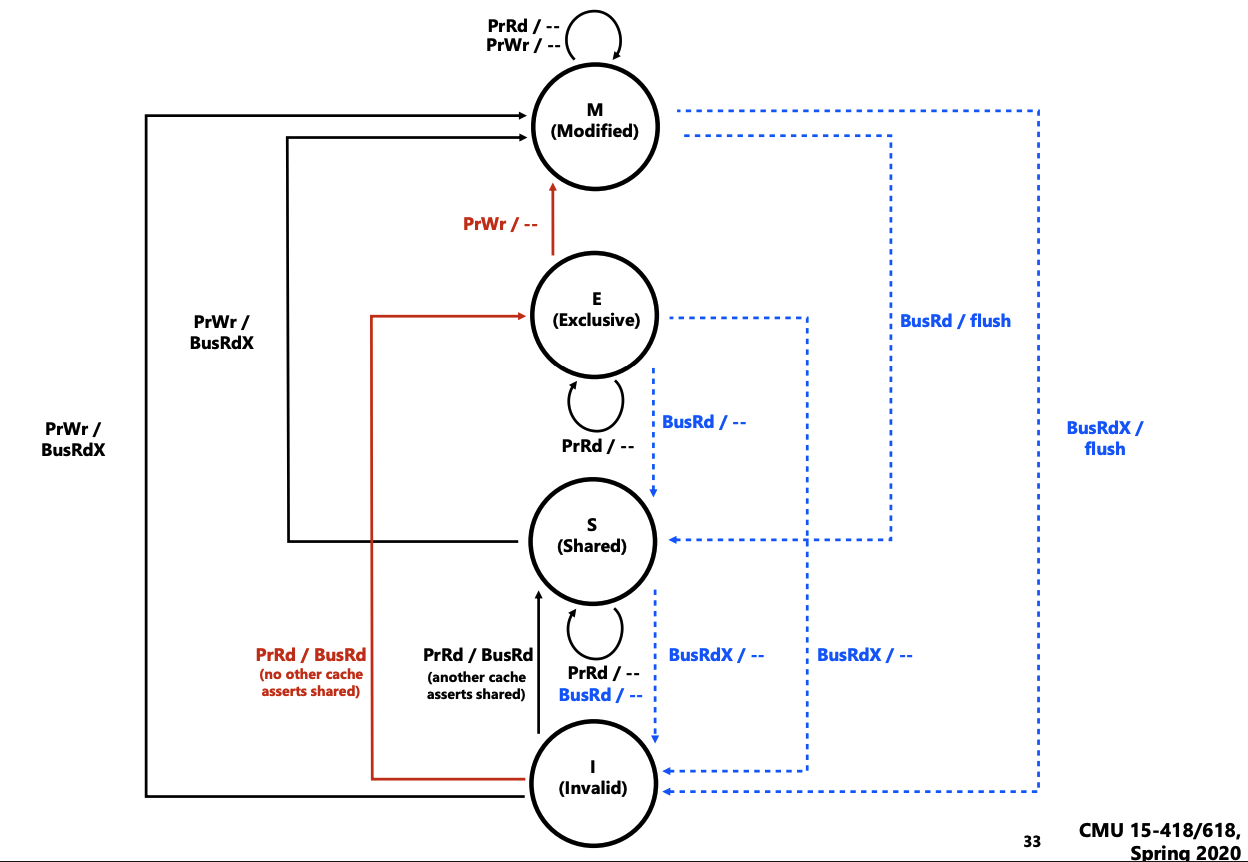
snoop-based coherence 是在缓存状态改变时,通过广播MESI 消息来维护各个cpu.
图中状态左侧部分表示,当前cpu 发起访存动作是要做的一些动作(包括发一些广播信号, 以 及置当前cacheline的状态)。而图中右侧则表示 cpu 被动的收到广播信号时, 所需要执行 的动作(包括置cacheline状态以及一些额外的动作, E.g. flush).
我们举一个例子,不展开各个状态。
如果当前cpu要write一个内存,该内存所对应的cache是 invalid(对应右侧I->M)
该cpu需要
- 发起
BusRdx消息广播. (BuxRdx表示一次写广播请求, 表示当前有人要写该 cacheline, 这里有一些serialization的问题这里不展开) - 将该内存地址对应的cacheline的状态由
I -> M - 执行
PrWr(PrWr表示cpu发起写操作,可以理解为改cacheline的内容了)
而其他cpu收到BusRdx后需要
- 将cacheline状态修改
X->I(X为M, E, S任意状态) - 如果是M状态, 可能还要执行
flush动作.(这里有一些序列化的问题, 例如这个flush 的动作要不要发生发起写操作的cpu的PrWr 之前)
snoop-based non-scalable 原因主要来自广播。每次cache miss(invalid)发生时,需要通知 其他所有的cache。而在numa架构下这个问题更为突出。
在numa架构下,软件尽可能的设计成numa亲和性方案,即让当前numa上cpu运行的程序,访 问该numa的内存,但是由于 snoop-based conherence 的存在, 当我们访问near memory时 还是需要向所有的cpu进行广播, 这导致软件层面的优化几乎不起作用。
于是大佬们在思考能不能不再广播,而是通过点对点的方式,向特定的cpu发送cache y conherence 消息。而这就需要一个数据库,记录cache在各个cpu中的状态,从而辅助 发起消息的cpu选择向哪些cpu发送。
directory-based
既然需要一个数据库,我们则维护一个名为directory 的database:
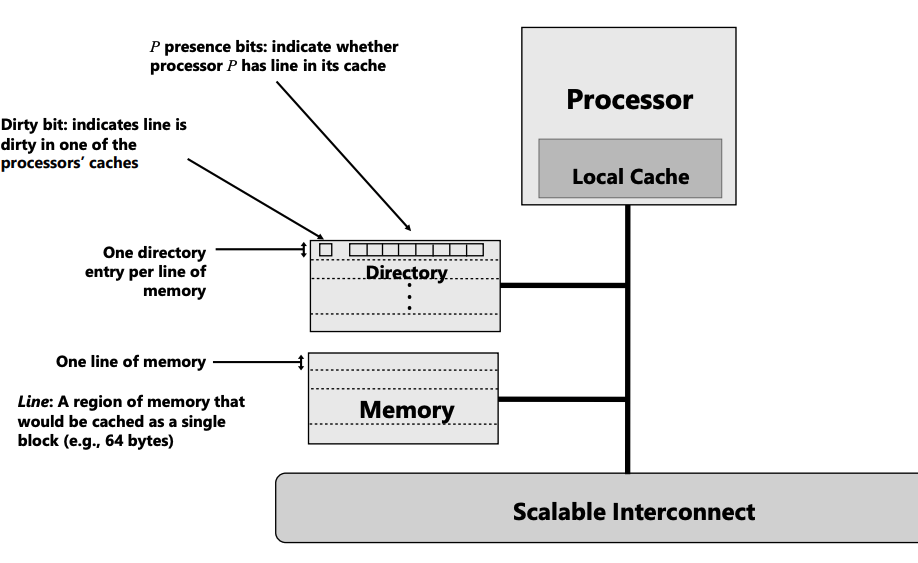 每个内存 在directory中维护了一个条目,每一个条目包括:
每个内存 在directory中维护了一个条目,每一个条目包括:
- Dirty bit: 表示在某个cpu-cache中。其缓存是dirty的。
- $p$ presence bit: 这是一个数组,每个字节表示该内存在其代表的cpu cache中 是否存在
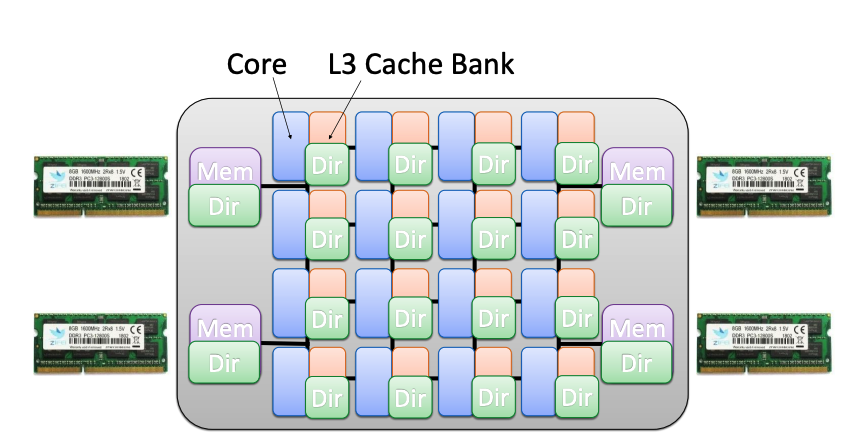 directory存在于L3 缓存组中(可能哈, 个人认为将l3当成了一个directory,该缓存条目中 除了包括常规的缓存信息外,还包括了和 directory 相关的信息。个人瞎猜).
directory存在于L3 缓存组中(可能哈, 个人认为将l3当成了一个directory,该缓存条目中 除了包括常规的缓存信息外,还包括了和 directory 相关的信息。个人瞎猜).
我们来看下两个场景, read miss to dirty line 和write miss(这对应于竞争较激烈的 spinlock场景)
read miss to dirty line
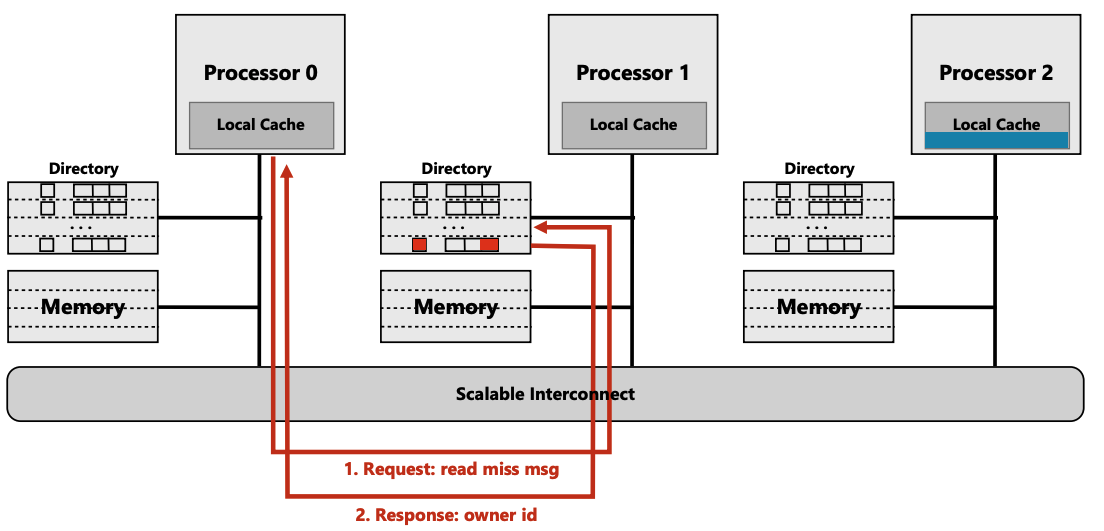
初始状态
- cpu 0 要访问 near cpu 1 memory
- cpu 0 中没有cache, directory entry dirtybit 为1
- cpu2 中有该地址的cache, 并且没有writeback, directory entry $p$ 中有 cpu 2
执行步骤:
- (步骤1)cpu 0 发起一个
read miss msg的request. - (步骤2)对应的memory 的 directory 查询其该条目中的 $p$ array, 查到cpu 2。并返 回消息给 cpu0
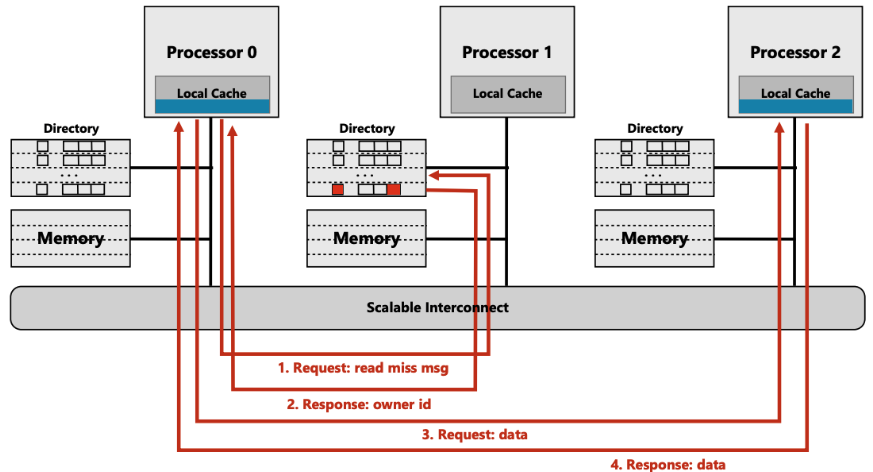
- (步骤3) cpu0 向cpu2 请求缓存内容
- (步骤4) cpu2 返回给cpu0
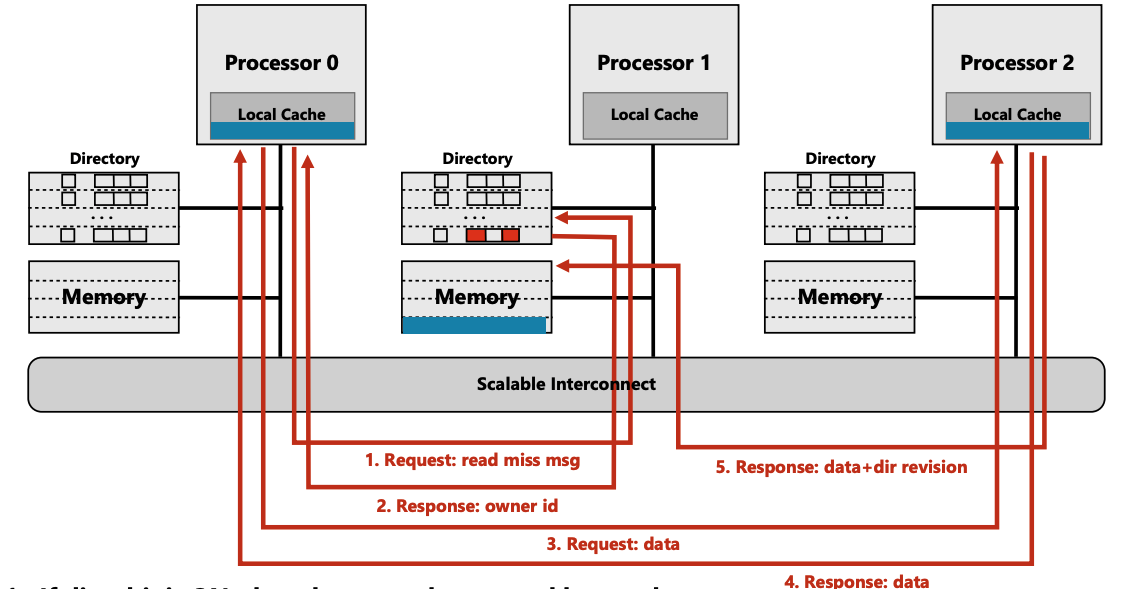
(步骤5) cpu2 返回给cpu1, dir的变更信息包括:cpu 0 请求了该cacheline,所以 $p$中 要置位 cpu0 bit
另外, 将dirty data 也传递到cpu1, cpu1 收到后,将dirty data flush 到memory, 并 clear dirty bit
non-scalable spinlock 的问题主要就在这一过程中,我们在之后的后面的章节中展开
我们接下来看下write miss
write-miss
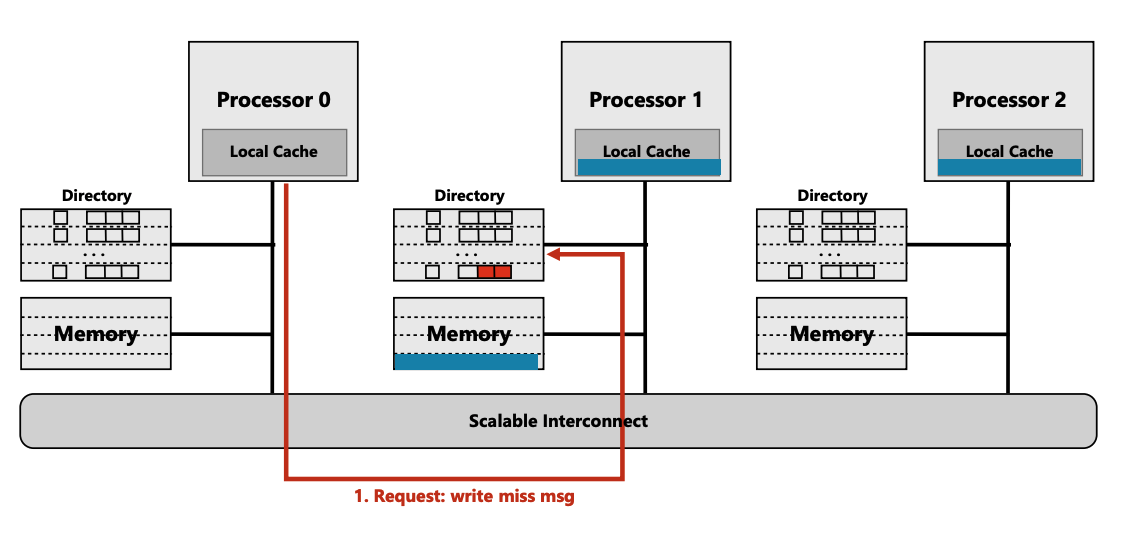
初始状态
- cpu0 要写 near cpu 1 memory
- cpu0 没有cache,directory entry dirtybit为0
- cpu0 没有cache, cpu1, cpu2 上有clean cache, $p$ 中有 cpu1, cpu2
执行步骤:
- (步骤1) cpu0 向directory 发 write miss msg
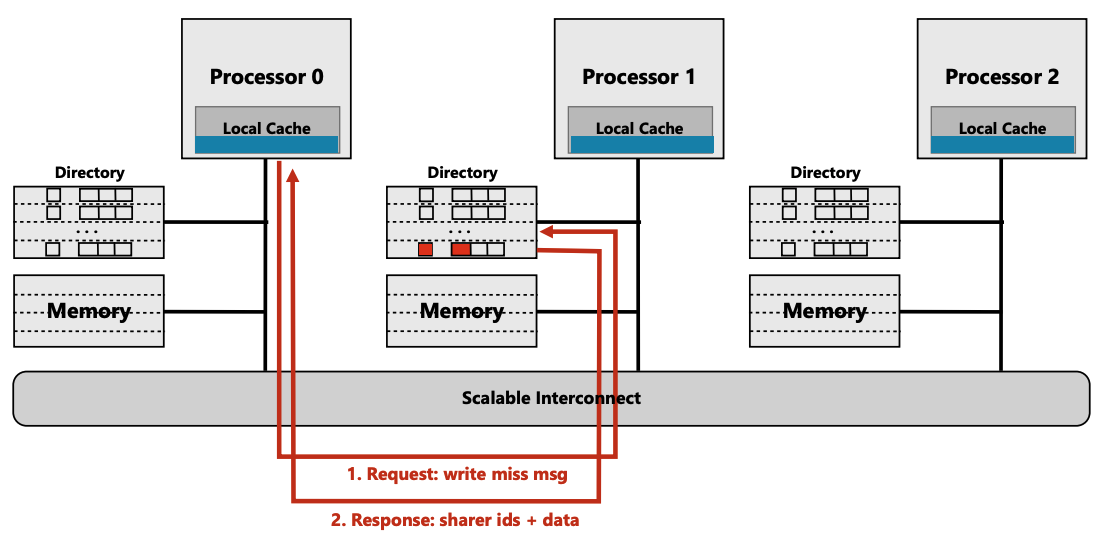
- (步骤2) 由于cache 是clear的, directory 直接将clear data + ids 返回给cpu0
- directory 修改 $p$
clean {0, 1, 1}–>dirty {1, 0, 0}
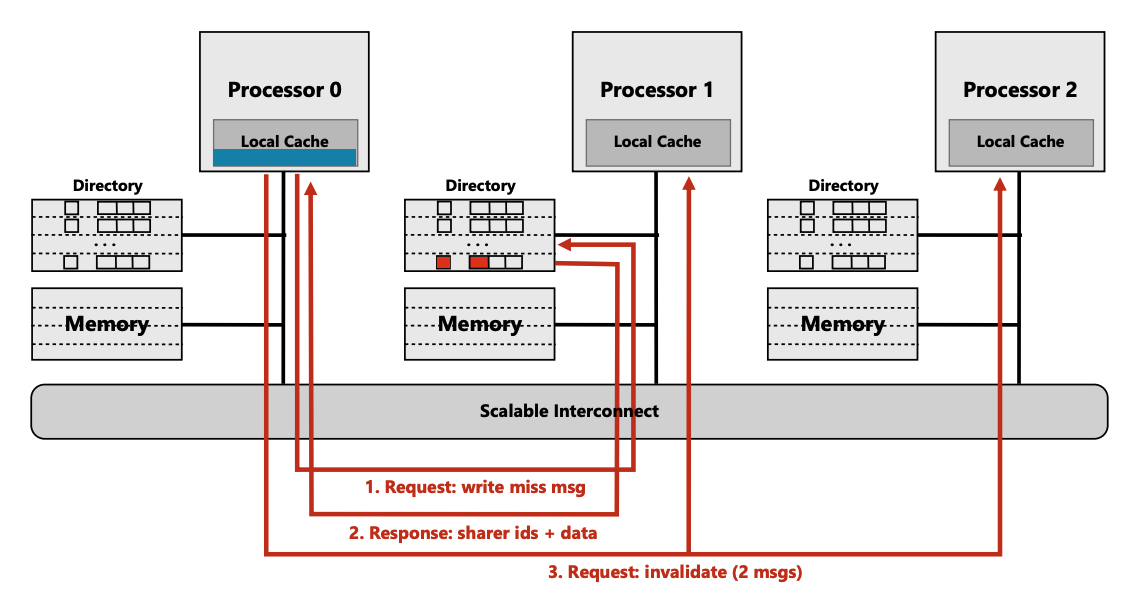
- (步骤3) cpu0 向cpu1, 2发送 invalid msg 消息
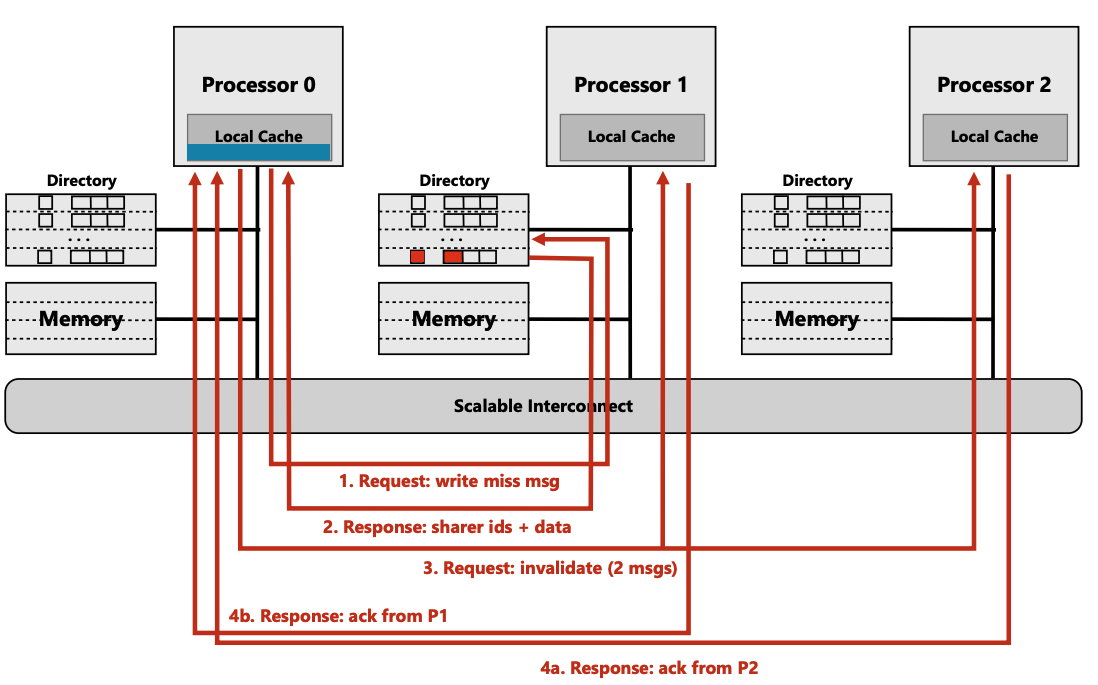
- (步骤4) cpu1, cpu2 发送ack 给cpu0
其实这个过程性能并不低,因为这是一个一对多,并且允许每个点对点的
{request, response}可以异步执行。但是这是一个触发器,其在spinlock过程中会将其他cpu的cache line invalid。 其他cpu 会如果再访问该内存会执行read miss流程…
文章4, 5介绍缓存一致性时,从
write-update,write-invalid角度展开 两个缓存一致性协议,个人查找资料发现write-update似乎不在主流的缓存一致性实现中 9大家可以设想下,
write-update一个好处是,在write操作发起时,会将cache 更新到 其他的缓存中,而不是让其失效。这样其他cpu 后续访问该缓存时,可以直接从当前 cpu local cache 中获取到干净的(而不是从主存)。但是只update 不invalid 会有明显的问题,因为被update 的cpu可能很长一段时间不会访问 该cache,而这段时间内如果有cpu write 这个地址,都会update 该cpu的cache。这会 造成很大的浪费。而基于 invalid 协议,会在写操作时invalid,在read时 触发cache-miss, 同时,也会从其他cpu的缓存中获取数据而不是直接从缓存获取, 总之,这种在 read-miss时按需获取再搭配 directory-based conherence 协议看起来比简单的 write-update 协议优秀很多。(当然可能cpu有一些更高级的预测功能,可以知道其他cpu可能在短时间 内需要访问这个cache(例如预取等等), 此时带宽又很空闲,会去做write-update? 但这远远 超出了我的知识范畴,也远远超出了本文要讲述的知识的范畴)
总之综上所述,本文接下来关于所有的cache conherence, 都不考虑write update, 均以write invalid 为例.
ok, 关于cache conherence 这个基础而又宏大的话题就再此戛然而止吧。我们来简单总结 下:
总结
snoop-based conherence在核非常多(尤其在numa架构下)面临着non-scalable的问题, 其主要的问题在于 MESI的各个消息都需要采用广播的机制。为了解决这一问题, 大佬们搞出了directory-based conherence,其通过点对点的方式,按需和某些cpu 消息 通信。
但是, 在某些场景下,这仍然造成了non-scalable的问题。
non-scalable spinlock
How to cause non-scalable
来设想下: non-scalable 一般是怎么出现的。往往是在资源扩张后(例如cpu数量), 执行 一些操作时,这些操作的复杂度往往会随着资源扩张线性增长。
而 spinlock 尤为突出,因为spinlock这种阻塞忙等性质的同步机制不仅会影响发起慢操 作的cpu运行,而且由于其阻塞性质,会影响全局的进度。
在介绍具体的触发机制之前,我们先来看下 non-scalable spinlock的实现方式
non-scalable spinlock implementation
wild spinlock
wild 的意思是粗暴, 未经训化的意思, 俗称原始人。我们也用比较原始的汇编 指令展现其简介性:
lock 代码
1
2
3
4
5
6
7
8
9
lock:
.long 0 # 锁变量,初始为0
spin_lock:
movl $1, %eax # eax = 1,表示“想要锁”
spin_loop:
xchgl %eax, [lock] # 原子交换 eax 和 lock
testl %eax, %eax # 判断之前的 lock 是否为0
jne spin_loop # 如果不为0,继续自旋
# 获取锁成功,继续执行临界区代码
unlock代码:
1
2
spin_unlock:
movl $0, lock # 直接写0,释放锁
但是 wild spinlock有个很大的问题。就是公平性。不同的cpu”看到”的[lock] 变为0的时间不同, 所以哪个核获取到锁充满了随机性。这种不公平性体现在 获取自旋锁的延迟极不稳定,而软件又往往期待平稳的延迟。
这个地方其实涉及同时发起atomic操作的串性执行的仲裁问题。这个仲裁是 有谁来做的,是如何排序pending的atomic操作。这些知识在本人的知识储备 外,代后续补充.
于是 ticket spinlock 闪亮登场。
ticket spinlock
ticket spinlock 会让每个自旋锁的申请者记录自己的”号牌”, 然后等待叫号. 这个很 像显示中的 排号系统。大家从排号机顺序取号,叫号时也会按顺序。
简单的小程序如下5:
数据结构
1
2
3
4
5
6
struct spinlock_t {
// 上锁者自己的排队号
int my_ticket;
// 当前叫号
int curr_ticket;
}
加锁:
1
2
3
4
5
6
7
8
void spin_lock(spinlock_t *lock)
{
int my_ticket;
// 顺位拿到自己的ticket号码;
my_ticket = atomic_inc(lock->my_ticket) - 1;
while (my_ticket != lock->curr_ticket)
; // 自旋等待!
}
解锁:
1
2
3
4
5
void spin_unlock(spinlock_t *lock)
{
// 呼叫下一位!
lock->curr_ticket++;
}
non-scalable ticket spinlock
我们以ticket spinlock为例来看下其在directory-based conherence 中 的non-scala.
按照ticket spinlock的设计, 当持有锁的cpu释放锁后,将会有一个确定的锁owner等待着 获取锁。但是按照前文提到的 directory-based conherence协议并不能第一时间让 这个确定的cpu看到,这就是矛盾所在。
我们来画图说明:
初始状态

初始状态为 CPU0 持有自旋锁,CPU1, CPU2 等待自旋锁。CPU 0 已经持有了一段时间, 此时CPU1, CPU2 中的cache已经更新为最近更新的值。
CPU0 解锁

CPU0 准备释放自旋锁,首先请求 directory 查询哪些cpu中还有该地址的cache, 并要求directory做一些invalid操作。

directory clean掉这些cpu bit,并且标记该cache 为dirty. 另外directory 将信息返回 cpu0.

CPU0 发起invalid cpu1, cpu2 该cache的请求。

CPU1, CPU2 返回该req处理完成。该cacheline已经被invalid
CPU2 read-miss
此时cpu2 仍然在自旋
1
while (my_ticket != lock->curr_ticket)
由于此时CPU0 在解锁过程中,将cpu 2的lock->curr_ticket更新了,cpu2的cacheline 被invalid,其读取会遇到 read-miss。

- cpu2 read-miss 需要向directory 发起请求
- directory 告诉cpu2这个cacheline 是 dirty 的,最新的数据在cpu0
- CPU2 向CPU0请求最新数据

CPU0 将最新的数据返回 
CPU0 请求directory 将请求flush cache(writeback)并请求更新ids(将CPU2 bit置位)
if cpu2 not own the update curr_ticket
如果CPU2 没有持有更新后的curr_ticket, 此时cpu2 仍然会自旋,而其他的cpu也会重复 cpu2 的流程,但是如果cpu特别多的话,directory 处理消息则会是瓶颈(假设directory 处理消息为串行).
见上图, CPU (0->9) 都自旋 curr_ticket, CPU5 是当前ticket的owner但是CPU5 “看到” 该cacheline的更新比较晚(接收到CPU 0 invalid REQ比较慢, 或者因为其他的一些原因) 导致其在directory 中排队比较靠后,所以在CPU5 即便是发出了 read-miss 相关的消息 后,也会延迟一段时间,等待directory 处理完前面排队的消息。参与wait spinlock的cpu 越多,该延迟越明显。
总结
本段用前面讲述的directory-based cache conherence协议 描述了ticket spinlock 在多核架构下的non-scalable 的底层原因。其原因主要是在消息通信过程中,会不可 避免的发生多对一的消息通信,导致”一”这一侧的处理成为了瓶颈。
接下来的章节我们将看下大佬们在 Linux kernel 侧的一些实践,将看到 non-scalable spinlock 是多么可怕么,并用数学方法解释相关现象。
non-scalable lock are dangerous
NOTE
本文主要是参照6
在实践过程中,大佬们发现system throughput(系统吞吐)会因non-scalable lock突然崩溃。例如,在系统在25 个核心的cpu 上运行的良好,但是在30个核心 CPU上运行却完全崩溃. 并且令人惊讶的是,造成崩溃的原因居然可以 临界区非常小 的锁。
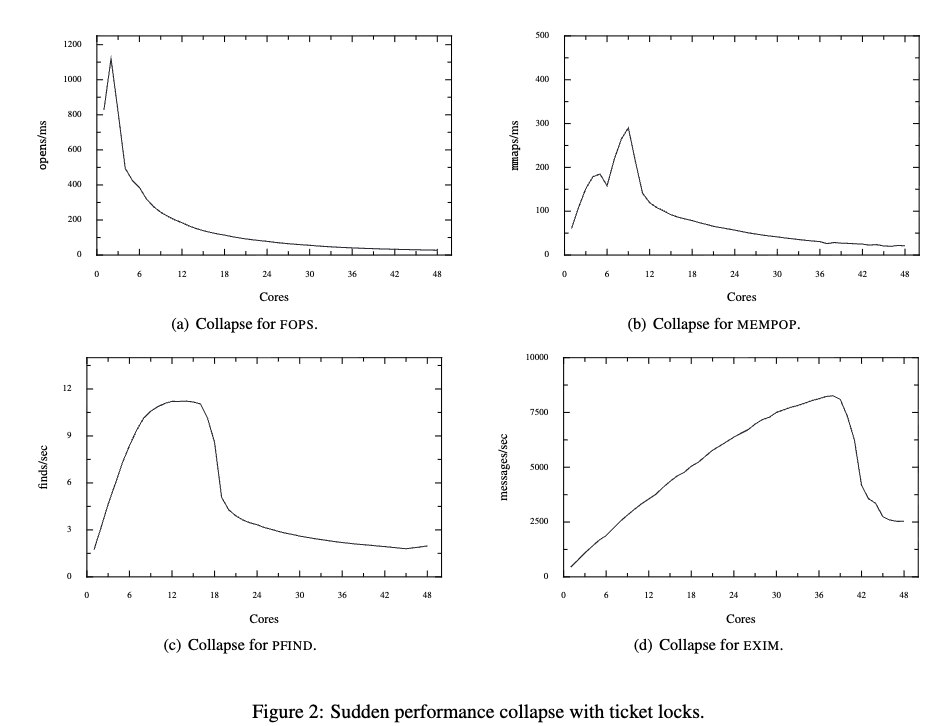
上图中的曲线有一些共同点,均是当Cpu和增长到一定的数量后,再增长几个核就会出现 极具的性能下降。
下图是各个负载的具体情况(其中EXIM, 是临界区特别小的场景)。
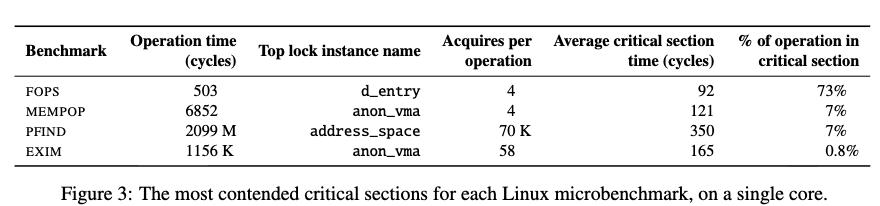
文中提出了几个问题:
- 为什么崩溃会如此早的开始 (例如FOPS 居然在3,4个核心就出发崩溃 )。
- 为什么性能会最终会大幅下降。
- 为什么性能会迅速下降。
为了解释上面这些问题,文中建立了马可夫链(Markov chain)模型。

一共有 $0, 1, 2, …. n$ 即$n + 1$个状态, $k$ 表示系统中共有 $k$ 个cpu在等待自旋 锁解锁。$A[k]$ 表示 状态从 $k$ 转换到 $k+1$ 的频率。(加锁的频率, 但是注意并不是 一个cpu申请锁的频率,而是 系统中共有$k$ 个等锁cpu到 $k+1$ 个等锁cpu的频率)。 而 $S[k]$
我们定义 $a$ 为单个核心上连续两次获取锁之间的平均时间。在没有竞争的情况下,单个 核心尝试获取锁的速率为 $\frac{1}{a}$, 因此,如果已有 k 个核心在等待锁,则新竞争 者的到达率为 $(n − k)/a$.( $n-k$ 增在从不等待自旋锁到等待自旋锁的状态,每个cpu的 频率为 $1/a$, 所以两者相乘). 因此图中的 $a[k]$为:
\[A[k] = \frac{n-k}{a} \tag{1}\]我们再关注下解锁阶段: $S[k]$ 。我们将 $S[k]$ 阶段所消耗的时间分为两部分,一部分 是临界区代码所消耗的时间, 记做$E$, 另一部分是$unlock$操作消耗的时间,记做 $R$。
根据我们上面讲的 directory-based cache conherence的简单模型,在解锁阶段有一些 流程需要是串行的。所以我们假设处理一个更新核心的cache所消耗时间为 $c$, 那么 $k$ 个核在等待相同自旋锁的情况下,将所有核的cache更新需要的时间为 $k \times c$, 但是 先处理哪个cpu,这个是随机的,所以curr_ticket owner cache 更新时间取个这些cpu更新 时间的平均值 $k \times c /2$, 那么可得:
可以看到 $S[k]$ 和$k$ 是成反比的关系。核心越多,更新cacheline的cost越高。
有了上面基本的结论,搭配下面一个稳态 Markov chain 状态转换率守恒的基本原则,即可 导出模型本身:
假設 $P_0, P_1, P_2, … P_n$ 系统处在这 $n$ 个状态的机率,显然 \(\sum P_k=1 \tag{3}\)
当系统处在稳态时,下方式子成立:
\[P_k \times A[k] = P_{k+1} \times S[k]\]这时一个递推, 结合(1), (2), (3)可以求出 $P_k$ 关于 $k$ 的表达式:
有了上面的公式,我们可以求出任意时刻整个系统等待自旋锁状态的CPU总量: (有1个cpu 等锁概率 * 1 + 有两个cpu等锁概率 * 2 + ... + 有n个cpu等锁 * n)
我们定义一个加速比的该你那,即在 $x$ 个cpu争抢 spinlock 时,有多少cpu未处于自旋锁 等锁的状态.
\[S=x - C\]下图是作者使用上面公式得到的推测值以及实际测试过程中得到的数据的对比图:
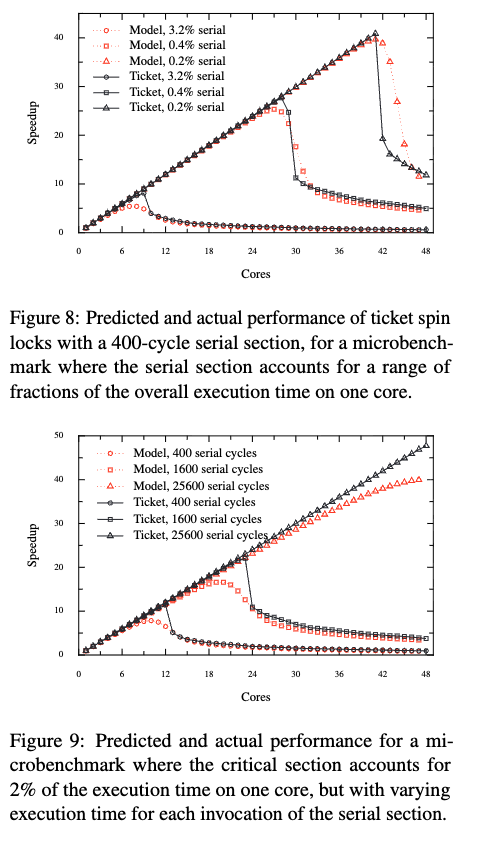
可以发现两者较为重合。
NOTE
上面公式本人未推导。均参考论文6以及狗哥文章4,5
scalable spinlock
NOTE
本文不讨论scalable spinlock的具体实现。关于这部分我们在另外一篇文章 介绍内核qspinlock的实现.
论文中提到了几种scalable spinlock并对这些锁做了性能测试.
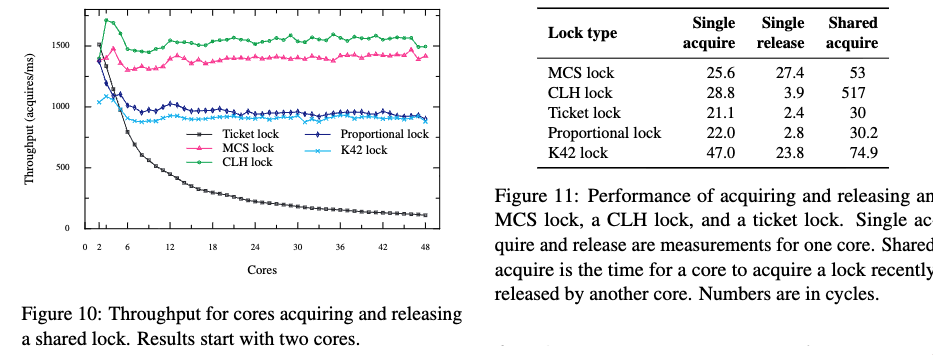
其中MCS和 CLH lock性能较好。
另外,作者还对比了 MCS vs ticket spinlock在上面提到的四种场景下的性能对比 :
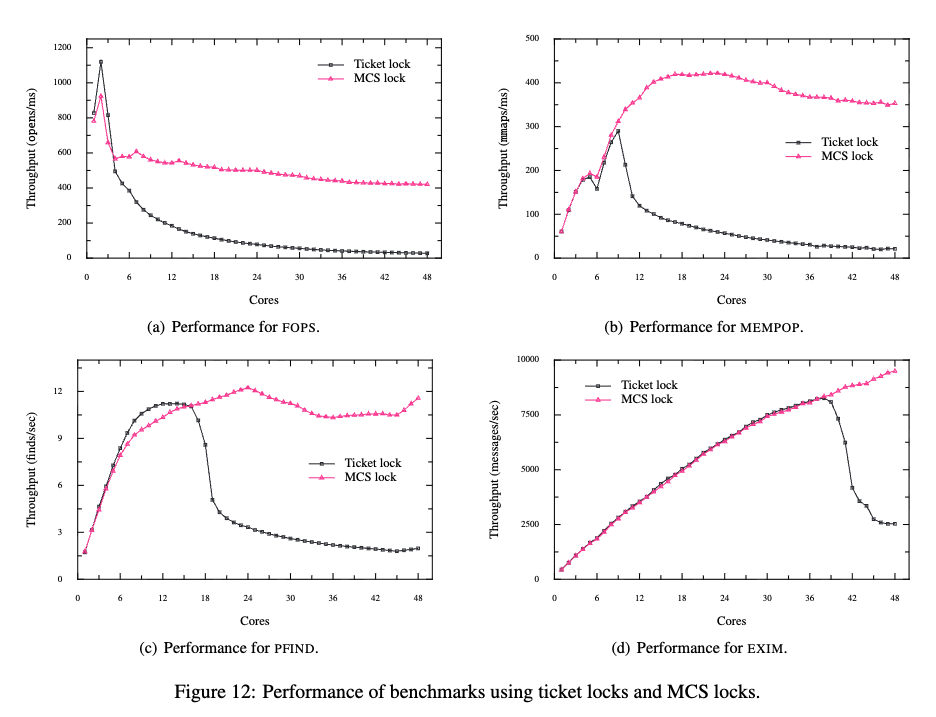
均取得了良好的效果。
NOTE
有小伙伴可能不理解为什么采用
scalable spinlock后仍然会导致性能吞吐量下降的问 题。但这并不是锁的消耗导致的。文章有一段介绍FOPS性能降低原因:Figure 12(a) shows the performance of FOPS with MCS locks. Going from one to two cores, performance with both ticket locks and MCS locks increases. For more than two cores, performance with the ticket spin lock decreases continuously. Performance with MCS locks initially also decreases from two to four cores, then re- mains relatively stable. The reason for this decrease in performance is that the time spent executing the critical section increases from 450 cycles on two cores to 852 cycles on four cores. The critical section is executed multiple times per-operation and modifies shared data, which incurs costly cache misses. As more cores are added, it is less likely that a core will have been the last core to execute the critical section, and therefore it will incur more cache misses, which will increase the length of the critical section
大概的意思是, 临界区中的代码会遇到较严重的cache miss, 核数越多,这种现象就越明 显(因为核数越多,下次运行到该核上的概率就越低)
另外大家可以想一下,即便是没有
cache-miss核数一直增长性能就会一直增长么?答案是肯定不是,因为这些程序并不全是完全并行的,要不就不会用到spinlock来保护 临界区。因为临界区的存在导致一部分流程必须串行。临界区越大的这种现象越明显。 而在结合临界区中因cache-miss而变长的情况,所以上面的测试得到的结果往往会 性能平稳的略微下降。
结论
non-scalable spinlock 会因 cache 一致性而造成非常严重的性能问题。通过替换scalable spinlock会大大缓解该问题。
参考链接
- Wikipedia: Spinlock
- Scalability
- 深入理解Linux内核之自旋锁
- sysprog: 从CPU cache一致性的角度看Linux spinlock的不可伸缩性(non-scalable)
- dog250: 从CPU cache一致性的角度看Linux spinlock的不可伸缩性(non-scalable)
- Non-scalable locks are dangerous
- Snooping-Based Cache Coherence
- Directory-Based Cache Coherence
- Cache Coherence - when do modern CPUs update invalidated cache lines